Cuando una persona dice que un evento es "probable" o "probable", la gente generalmente tiene una comprensión común, aunque vaga, de lo que eso significa. Pero cuando un chatbot de IA como ChatGPT usa la misma palabra, no evalúa las probabilidades como lo hacemos nosotros, descubrimos mis colegas y yo.
Recientemente publicamos un estudio en la revista NPJ Complexity que sugiere que, si bien las IA con modelos de lenguaje grandes destacan en la conversación, a menudo no logran igualar a los humanos cuando se comunican sobre la incertidumbre. La investigación se centró en palabras de probabilidad estimada, que incluyen términos como "tal vez", "probablemente" y "casi seguro".
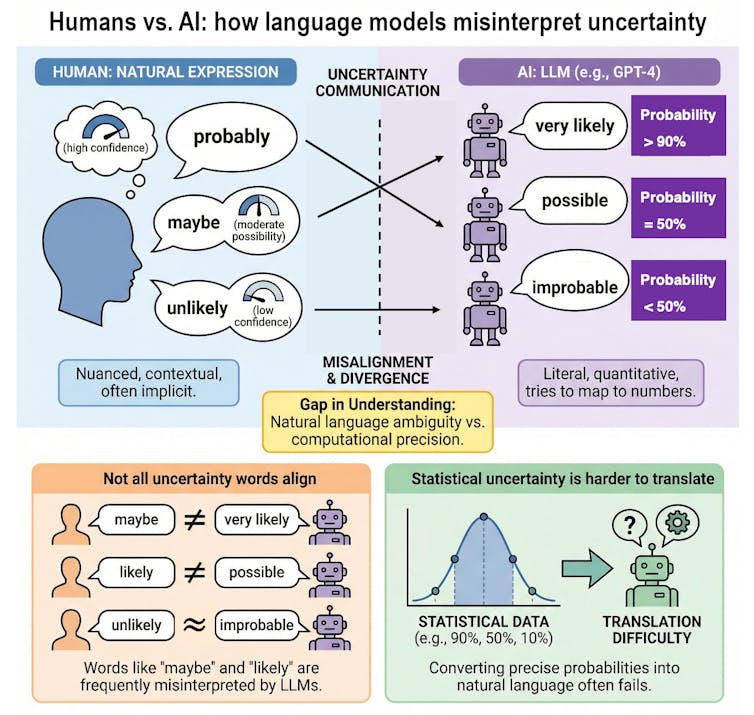
Al comparar cómo los modelos de IA y los humanos asignan estas palabras a porcentajes numéricos, encontramos brechas significativas entre los humanos y los grandes modelos de lenguaje. Si bien los modelos tienden a estar de acuerdo con los humanos en extremos como "imposible", discrepan marcadamente en palabras como "tal vez". Por ejemplo, un modelo podría usar la palabra "probable" para representar una probabilidad del 80%, mientras que un lector humano supone que significa más cerca del 65%.
Esto podría deberse a que las personas pueden interpretar palabras como "probablemente" y "probablemente" basándose en señales contextuales y experiencias personales. Por el contrario, los modelos de lenguaje grandes pueden promediar los usos conflictivos de esas palabras en sus datos de entrenamiento, lo que lleva a desviaciones de las interpretaciones humanas.
Nuestro estudio también encontró que los modelos de lenguaje grandes son sensibles al lenguaje de género y al lenguaje específico utilizado para las indicaciones. Cuando el mensaje cambió de "él" a "ella", las estimaciones de probabilidad de la IA a menudo se volvieron más rígidas, reflejando sesgos integrados en los datos de entrenamiento. Cuando el mensaje se cambia del inglés al chino, las estimaciones de probabilidad de la IA a menudo cambian, posiblemente debido a diferencias entre el inglés y el chino en la forma en que las personas expresan y entienden la incertidumbre.
Los chatbots de IA no interpretan "probablemente" y "tal vez" de la misma manera que usted. Mayank Kejriwal Por qué es importante
Lejos de ser una peculiaridad lingüística, este desajuste es un desafío fundamental para la seguridad de la IA y la interacción entre humanos y IA. A medida que los grandes modelos lingüísticos se utilizan cada vez más en áreas de alto riesgo como la atención sanitaria, las políticas gubernamentales y los informes científicos, la forma en que comunican el riesgo se convierte en una cuestión de confianza pública.
Si un asistente de IA que ayuda a un médico, por ejemplo, describe un efecto secundario como "improbable", pero el cálculo interno del modelo de "improbable" es mucho mayor que la interpretación del médico, la decisión resultante podría ser errónea.
¿Qué otras investigaciones se están realizando?
Los científicos han estudiado cómo la gente cuantifica la incertidumbre desde la década de 1960, un campo en el que fueron pioneros los analistas de la CIA para mejorar los informes de inteligencia. Más recientemente, ha habido una explosión en la gran literatura sobre modelos de lenguaje que intenta mirar bajo el capó de las redes neuronales para comprender mejor su "comportamiento" y patrones de lenguaje.
Nuestro estudio añade una capa de complejidad al tratar la interacción entre los humanos y la inteligencia artificial como un sistema biológico en el que el significado puede degradarse. Va más allá de simplemente medir si una IA es "inteligente" y, en cambio, pregunta si cumple con las normas.
Otros investigadores están investigando actualmente si el llamado pensamiento en cadena (pedirle a la IA que demuestre su trabajo) puede corregir estos errores. Sin embargo, nuestro estudio encontró que incluso el razonamiento avanzado no siempre cierra la brecha entre los datos estadísticos y las etiquetas verbales.
¿Qué sigue?
El objetivo del futuro desarrollo de la IA es crear modelos que no sólo predigan la siguiente palabra probable, sino que realmente comprendan el peso de la incertidumbre que transmiten. Los investigadores piden métricas de coherencia más sólidas para garantizar que si el modelo ve una probabilidad del 10% en los datos, elija la misma palabra cada vez.
A medida que avanzamos hacia un mundo donde la IA resume artículos científicos y gestiona los horarios de las personas, asegurarse de que "probablemente" signifique "probablemente" es un paso vital para que estos sistemas sean socios confiables, no sólo loros sofisticados.
El Research Brief es una breve descripción de trabajos académicos interesantes.


.webp)








0 Comentarios